设计模式
特定设计模式
Asynchronous Request-Reply Pattern
服务端马上返回客户端请求,并且异步处理任务,客户端可以稍后查询任务状态
何时使用
| 应用 | 功能 | 需要关注 |
|---|---|---|
| CPU-bound | 查询任务状态 |
需要关注
HTTP status code
There are a number of possible ways to implement this pattern over HTTP and not all upstream services have the same semantics. For example, most services won't return an HTTP 202 response back from a GET method when a remote process hasn't finished. Following pure REST semantics, they should return HTTP 404 (Not Found). This response makes sense when you consider the result of the call isn't present yet.
Perform long-running tasks with the webhook action pattern
Legacy clients might not support this pattern. In that case, you might need to place a facade over the asynchronous API to hide the asynchronous processing from the original client. For example, Azure Logic Apps supports this pattern natively can be used as an integration layer between an asynchronous API and a client that makes synchronous calls. See Perform long-running tasks with the webhook action pattern.
如何执行
具体策略请浏览:
Compensating Transaction pattern
使用事务补偿的方式使多步骤的事务保持最终一致性
何时使用
| 应用 | 功能 | 需要关注 |
|---|---|---|
| Uber | 叫车流程中出错(叫到车但是司机取消,自动重新叫车)还原司机以及乘客状态 | Retry |
| File Sync | 文件同步过程出错(文件夹名被占用,自动修改),还原文件状态 | Retry |
需要关注
Order
The order of the steps in the compensating transaction doesn't necessarily have to be the exact opposite of the steps in the original operation. For example, one data store might be more sensitive to inconsistencies than another, and so the steps in the compensating transaction that undo the changes to this store should occur first.
Fail
A compensating transaction is also an eventually consistent operation and it could also fail. The system should be able to resume the compensating transaction at the point of failure and continue. It might be necessary to repeat a step that's failed, so the steps in a compensating transaction should be defined as idempotent commands.
Retry logic
Only stop the operation and initiate a compensating transaction if a step fails repeatedly or cannot be recovered.
如何执行
具体策略请浏览:
Competing Consumers pattern
Event Sourcing pattern
使用 append-only 的方式来记录所有数据的变化,方便进行数据溯源以及保证了数据的一致性,也能提供事务补偿功能。
何时使用
| 应用 | 功能 | 需要关注 |
|---|---|---|
| Shopping | 购物的整个流程拆分成不同的事件 | |
| Ranking | 每次用户使用该数据(Hashtag,听歌)则产生多个事件 |
需要关注
Eventually consistent
The system will only be eventually consistent when creating materialized views or generating projections of data by replaying events. There's some delay between an application adding events to the event store as the result of handling a request, the events being published, and consumers of the events handling them. During this period, new events that describe further changes to entities might have arrived at the event store.
Difficult to update
If the format (rather than the data) of the persisted events needs to change, perhaps during a migration, it can be difficult to combine existing events in the store with the new version.
Idempotent
Event publication might be at least once, and so consumers of the events must be idempotent.
如何执行
具体策略请浏览:
CQRS pattern
分开读和写的操作以及存储,通常和 Event Sourcing pattern 与 Materialized View pattern 一起使用
何时使用
| 应用 | 功能 | 需要关注 |
|---|---|---|
| Shopping | 购物的整个流程拆分成不同的事件 | |
| Ranking | 每次用户使用该数据(Hashtag,听歌)则产生多个事件 |
需要关注
Messaging
Although CQRS does not require messaging, it's common to use messaging to process commands and publish update events. In that case, the application must handle message failures or duplicate messages. See the guidance on Priority Queues for dealing with commands having different priorities.
Eventual consistency
If you separate the read and write databases, the read data may be stale. The read model store must be updated to reflect changes to the write model store, and it can be difficult to detect when a user has issued a request based on stale read data.
如何执行
具体策略请浏览:
Gatekeeper pattern
使用 Gateway 去验证和处理请求,提高系统安全性
何时使用
| 应用 | 功能 | 需要关注 |
|---|---|---|
| Shopping | 限制流量以及服务降级 | |
| Video | 流量分发以及负载均衡 | |
| Trading | 流量验证以及安全防护 |
需要关注
Security
Ensure that the trusted hosts the gatekeeper passes requests to expose only internal or protected endpoints and connect only to the gatekeeper. The trusted hosts shouldn't expose any external endpoints or interfaces.
Single point of failure
The gatekeeper instance could be a single point of failure. To minimize the impact of a failure, consider deploying additional instances and using an autoscaling mechanism to ensure capacity to maintain availability.
如何执行
具体策略请浏览:
Geode pattern
根据地理位置将请求导向最优的服务器/数据库处理请求。
何时使用
| 应用 | 功能 | 需要关注 |
|---|---|---|
| Live | 减少浏览直播的延迟,多级缓存和大量重复请求处理 | - |
| Video | 减少浏览直播的延迟,多级缓存和大量重复请求处理 | Cache |
需要关注
Log Analytics
Consider how to track different components of the same request as they might execute asynchronously on different instances. A proper monitoring strategy is crucial.
如何执行
具体策略请浏览:
Rate Limiting pattern
节流模式用于减少流量以及增加带宽吞吐量,节流策略可以从每秒请求数,请求数据量,费用等维度进行配置。
何时使用
| 应用 | 功能 | 需要关注 |
|---|---|---|
| Live | 对流量进行限制 | - |
| Video | 对流量进行限制 | - |
| Shopping | 对流量进行限制 | - |
需要关注
Durable messaging system
In scenarios where your APIs can handle requests faster than any throttled ingestion services allow, you'll need to manage how quickly you can use the service. However, only treating the throttling as a data rate mismatch problem, and simply buffering your ingestion requests until the throttled service can catch up, is risky. If your application crashes in this scenario, you risk losing any of this buffered data.
Improve throughput
While not required, it's often recommended to send smaller amounts of records more frequently to improve throughput. So rather than trying to batch things up for a release once a second or once a minute, you can be more granular than that to keep your resource consumption (memory, CPU, network, etc.) flowing at a more even rate, preventing potential bottlenecks due to sudden bursts of requests. For example, if a service allows 100 operations per second, the implementation of a rate limiter may even out requests by releasing 20 operations every 200 milliseconds, as shown in the following graph.
Errors handle
While the rate limiting pattern can reduce the number of throttling errors, your application will still need to properly handle any throttling errors that may occur.
Integrate multiple workstreams into rate limiting strategy
If your application has multiple workstreams that access the same throttled service, you'll need to integrate all of them into your rate limiting strategy. For instance, you might support bulk loading records into a database but also querying for records in that same database. You can manage capacity by ensuring all workstreams are gated through the same rate limiting mechanism. Alternatively, you might reserve separate pools of capacity for each workstream.
如何执行
具体策略请浏览:
相关组件
| 名称 | 特点 | 阅读 |
|---|---|---|
| Google Cloud Armor |
| Cloud Armor Key features |
| Amazon API Gateway |
| Amazon API Gateway Features |
Saga distributed transactions pattern
Saga 是一种故障处理 pattern,用于分布式应用程序中建立一致性,并协调多个微服务之间的事务以保持数据一致性。其使用 Choreography 和 Orchestration 实现 Compensating Transaction pattern
何时使用
| 应用 | 功能 | 需要关注 |
|---|---|---|
| Uber | 叫车流程中出错(叫到车但是司机取消,自动重新叫车)还原司机以及乘客状态 | Retry |
| File Sync | 文件同步过程出错(文件夹名被占用,自动修改),还原文件状态 | Retry |
需要关注
idempotence
The implementation must be capable of handling a set of potential transient failures, and provide idempotence for reducing side-effects and ensuring data consistency.
Lost updates, Dirty reads
Lost updates, when one saga writes without reading changes made by another saga. Dirty reads, when a transaction or a saga reads updates made by a saga that has not yet completed those updates.
如何执行
Choreography
Choreography is a way to coordinate sagas where participants exchange events without a centralized point of control. With choreography, each local transaction publishes domain events that trigger local transactions in other services.
Orchestration
Orchestration is a way to coordinate sagas where a centralized controller tells the saga participants what local transactions to execute. The saga orchestrator handles all the transactions and tells the participants which operation to perform based on events. The orchestrator executes saga requests, stores and interprets the states of each task, and handles failure recovery with compensating transactions.
具体策略请浏览:
Sharding pattern
对数据存储进行水平划分,提高系统的 scalability 和 availability
何时使用
| 应用 | 功能 | 需要关注 |
|---|---|---|
| Newsfeed | 对 news 进行 sharding | |
| Live | 对 video 进行 sharding | |
| search | 对查询内容进行 sharding |
需要关注
Rebalance
Rebalancing can be an expensive operation. To reduce the necessity of rebalancing, plan for growth by ensuring that each shard contains sufficient free space to handle the expected volume of changes. You should also develop strategies and scripts you can use to quickly rebalance shards if this becomes necessary.
Use stable data for the shard key
avoid basing the shard key on potentially volatile information. Instead, look for attributes that are invariant or that naturally form a key.
如何执行
具体策略请浏览:
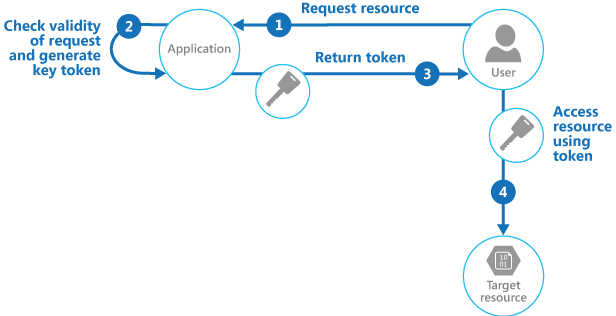
Valet Key pattern
使用 token 进行鉴权,使用户可以直接访问资源,无需每次都经过服务器
何时使用
| 应用 | 功能 | 需要关注 |
|---|---|---|
| Newsfeed | 上传图片和视频 | |
| Infrastructure | 认证调用者,记录 quota |
需要关注
Manage the validity status and period of the key.
A key can usually be revoked or disabled, depending on how it was issued. Server-side policies can be changed or, the server key it was signed with can be invalidated. Specify a short validity period to minimize the risk of allowing unauthorized operations to take place against the data store. However, if the validity period is too short, the client might not be able to complete the operation before the key expires.
Control the level of access the key will provide
Typically, the key should allow the user to only perform the actions necessary to complete the operation, such as read-only access if the client shouldn't be able to upload data to the data store.
Deliver the key securely
It can be embedded in a URL that the user activates in a web page, or it can be used in a server redirection operation so that the download occurs automatically. Always use HTTPS to deliver the key over a secure channel.
如何执行
具体策略请浏览:
通用设计模式
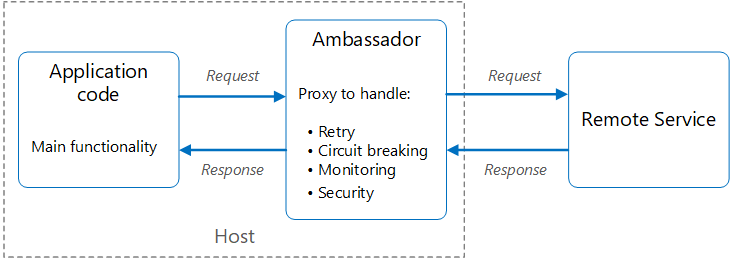
Ambassador pattern
使用一个适配器来管理新系统与旧系统直接的数据交换
需要关注
Latency
The proxy adds some latency overhead. Consider whether a client library, invoked directly by the application, is a better approach.
Idempotent
Consider the possible impact of including generalized features in the proxy. For example, the ambassador could handle retries, but that might not be safe unless all operations are idempotent.
如何执行
具体策略请浏览:
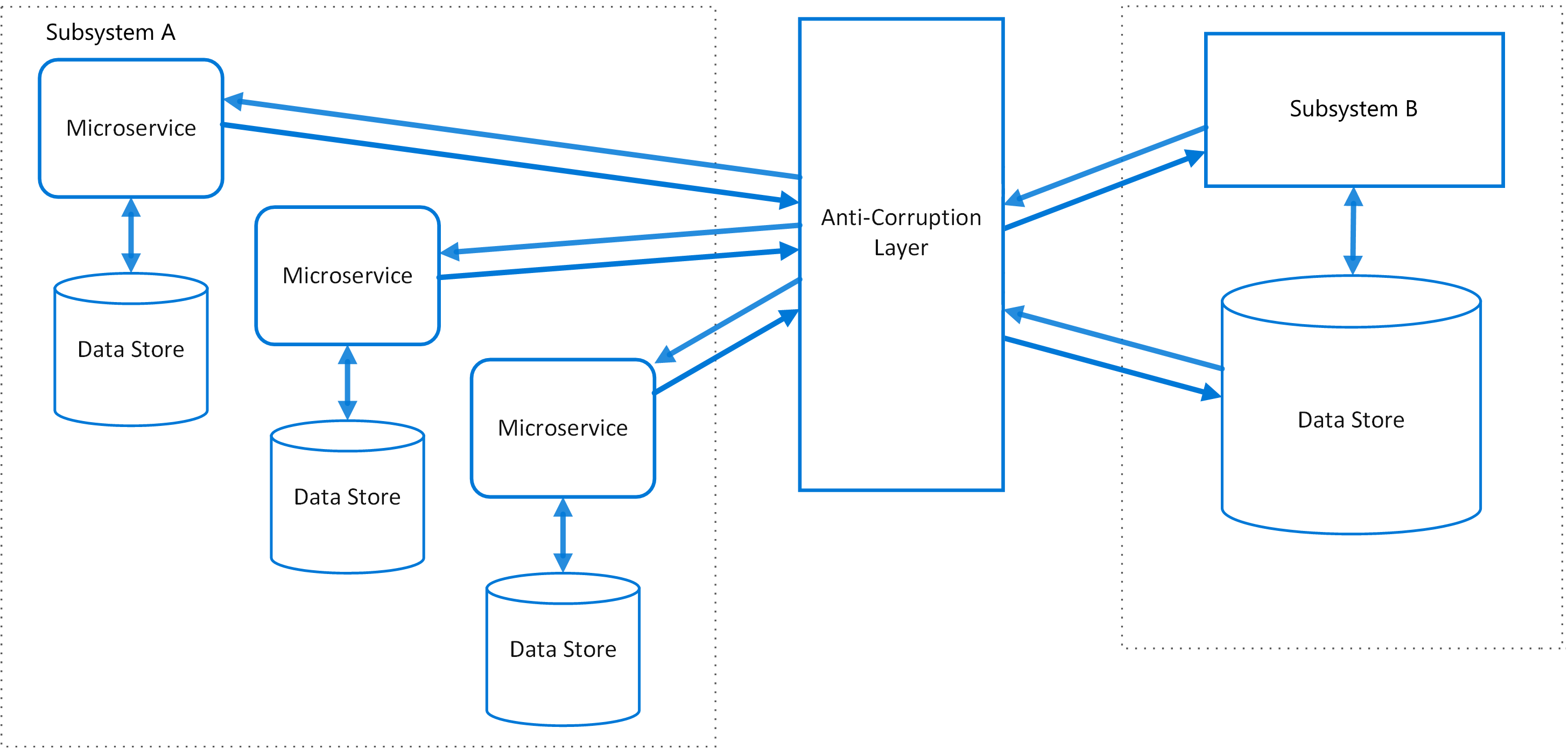
Anti-corruption Layer pattern
使用一个适配器来管理新系统与旧系统直接的数据交换
何时使用
| 应用 | 功能 | 需要关注 |
|---|---|---|
| Infrastructure | 框架迁移,新旧系统交互 |
需要关注
Latency
The anti-corruption layer may add latency to calls made between the two systems.
Transaction
Make sure transaction and data consistency are maintained and can be monitored.
如何执行
具体策略请浏览:
Cache-Aside pattern
使用缓存组件对数据进行分级存储,提高读取速度
何时使用
| 应用 | 功能 | 需要关注 |
|---|---|---|
| Video | 使用 CDN 和 POP 缓存热门视频 | 热门视频提前预热,定时更新缓存视频 |
| Ranking | 对排名结果进行缓存 | 定期计算排名并且更新缓存 |
| Search | 对搜索结果进行缓存 | 定期计算搜索结果并且更新缓存 |
需要关注
Lifetime of cached data
Don't make the expiration period too short because this can cause applications to continually retrieve data from the data store and add it to the cache. Similarly, don't make the expiration period so long that the cached data is likely to become stale.
Evicting data
Most caches adopt a least-recently-used policy for selecting items to evict, but this might be customizable.
Priming the cache
Many solutions prepopulate the cache with the data that an application is likely to need as part of the startup processing.
Consistency
Implementing the Cache-Aside pattern doesn't guarantee consistency between the data store and the cache.
Local (in-memory) caching
This data could quickly become inconsistent between caches, so it might be necessary to expire data held in a private cache and refresh it more frequently. In these scenarios, consider investigating the use of a shared or a distributed caching mechanism.
如何执行
读取数据:
- 检查缓存是否有数据,有的话从缓存返回
- 如果没有的话,从持久化存储中读取数据
- 将数据写入缓存
写数据:
- 将数据写入持久化存储
- 从缓存删除数据
相关组件
| 名称 | 特点 | 阅读 |
|---|---|---|
| Redis |
| Introduction to Redis |
| Memorystore |
| Memorystore |
| Amazon ElastiCache |
| Amazon ElastiCache features |
Health Endpoint Monitoring pattern
定时请求服务器检查其健康状况
何时使用
| 应用 | 功能 | 需要关注 |
|---|
需要关注
How to validate the response.
While this provides the most basic measure of application availability, and is the minimum implementation of this pattern, it provides little information about the operations, trends, and possible upcoming issues in the application.
Security
To protect them from public access, which might expose the application to malicious attacks, risk the exposure of sensitive information, or attract denial of service (DoS) attacks.
如何执行
具体策略请浏览:
Retry pattern & Circuit Breaker pattern
使用代理策略对重试功能进行管理和限制,防止出现大量重试导致原本崩溃的组件无法恢复以及耗用过多重试资源。
何时使用
| 应用 | 功能 | 需要关注 |
|---|---|---|
| News Feed | 对消息发送失败进行重试 | Exception Handling, Logging |
| IM | 对消息发送失败进行重试 | Exception Handling, Logging |
| File Sync | 对业务操作进行重试(更新文件) | Retry after delay |
需要关注
Retry Issues and considerations Circuit Breaker Issues and considerations
Fail fast
For some noncritical operations, it's better to fail fast rather than retry several times and impact the throughput of the application.
Exception Handling
A request to a service can fail for a variety of reasons raising different exceptions depending on the nature of the failure. Some exceptions indicate a failure that can be resolved quickly, while others indicate that the failure is longer lasting. It's useful for the retry policy to adjust the time between retry attempts based on the type of the exception.
Idempotent
retries could cause the operation to be executed more than once, with unintended side effects
Logging
It's important to log all connectivity failures that cause a retry so that underlying problems with the application, services, or resources can be identified.
如何执行
具体策略请浏览: